Succeed by designing machine learning products that fail
Key design traits for successful machine learning products

Computers are dumb. They’ve gotten faster throughout the decades, though, and programmers have increasingly stacked up larger amounts of simple instructions to make computers do ‘smart’ things. Computers, for their part, are happy to execute these instructions over and over again. Since the 1980s, when white collar workers began to use Lotus 1–2–3 to automate spreadsheets, software has subtly trained its users to expect predictable behavior. One interface may be more confusing than the next, but all users implicitly know that when one hits Play, the video should play. If it does not, something is wrong.
Now, in the era of machine learning, computers are a new kind of strict instructions: to teach themselves how to accomplish tasks. Drawing on computers’ power to do millions of instructions at once, these applications unlock amazing possibilities — like machine translation or comparing your selfie to historical paintings — that were once impossible to pull off via a programmer’s explicit instructions.
Computers, though, have not achieved sudden sentience. Machine learning systems are never 100% correct. Product design with machine learning, has a huge difference from previous software design paradigms:
Error is not an exception; it is a constant.
Successful machine learning software must be designed from first principles to harness the interplay between rapid computational judgments and accurate human insights. Error handling can no longer be done with a red banner or a dialog box. It’s now a fundamental design requirement, but the good news is, there are emerging best practices and useful frameworks to think through the problem.
Icarus.ai: binary products fly close to the sun
Alexa is incredibly complex: it understands phonemes, extracts meaning and content from language, and interfaces with thousands of sub-services to answer queries.
That said, Alexa frequently misunderstands my wife. After Alexa says she doesn’t know how to “turn the lights awful,” my wife is innately compelled to repeat her question with a tone of voice that implies Alexa is actually a four-year-old refusing to eat her green beans.
Alexa gets one thing wrong and the user is instantly frustrated. Alexa isn’t an outlier; there’s an entire SiriFail subreddit. The traditional call-and-response “AI assistant” model has only one shot to get the answer right. Even for tech mega-companies like Amazon and Apple, it leads to frequently frustrated users — who expect software to behave logically.
Google Photos is incredibly impressive: in March 2015, Google released its FaceNet paper that outlined the methodology used for facial recognition. On a widely recognized benchmark, FaceNet was 99.63% accurate. Just a few months later, in July, a scandal erupted when Google’s facial recognition models recognized two African-Americans as “gorillas.” The algorithm at fault may or may not have been FaceNet, but it’s clear that if one user becomes part of that 0.37% of error, the accuracy experienced by most of the population becomes quickly irrelevant.
These apps use ML for binary outcomes. They are right or wrong: there is no gray area with text-to-speech, facial recognition, or many types of natural language understanding. The accuracy of the model controls the success of the product, and some disappointment is probabilistically inevitable. On the flip side, when these applications succeed, they open up new possibilities in software and society.
Gradual ML products silently move us forward
Alexa, Siri, and facial recognition apps are visible; they delight and disappoint us on a daily basis. However, there are numerous AI/ML products that we use just as often that don’t drive the same frustrations that the other systems do.
8 million shows, still nothing to watch…
When I sit down to watch something on Netflix, a melange of ML algorithms are guiding my selections. Over 80% of Netflix users’ viewing choices are driven by Netflix’s ML recommendation system. Google and Amazon return search results; Spotify’s Discover Weekly finds new music; all systems enhanced by AI techniques.
These apps make gradual predictions—the accuracy of the model contributes to, but does not control, the success of the product. Users have lower expectations and allow these systems the latitude to improve over time. Whether your new favorite song showed up first or tenth in the recommendation list is immaterial; whether Lyft found you the absolute best driver or just the third-best is completely unclear; your expectations are managed.
Mitigating risks in ML product design
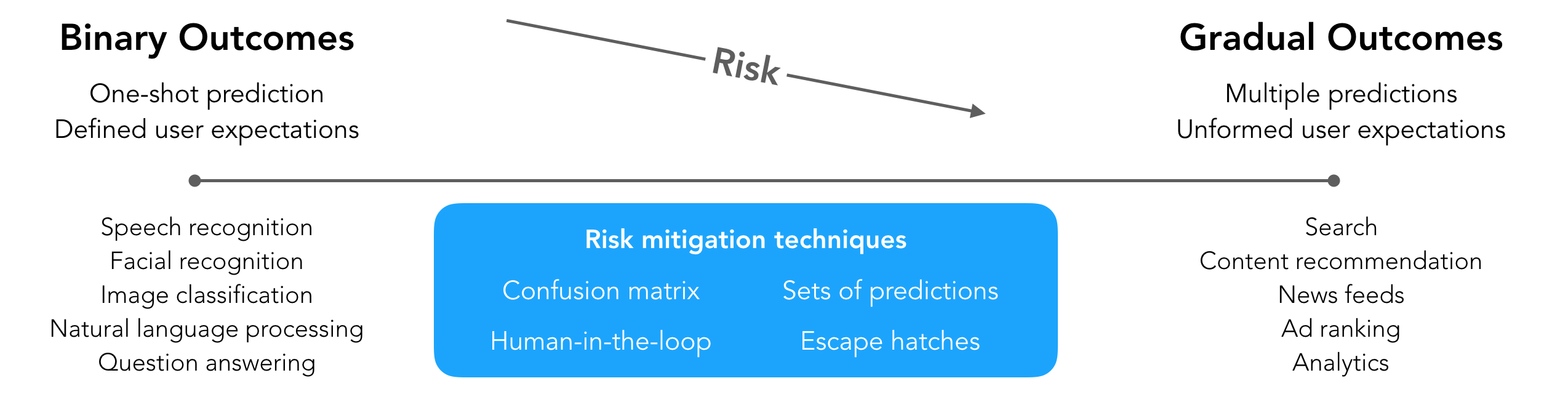
Building successful machine learning products involves navigating a complex soup of user expectations, workflow requirements, and design of fallbacks and suggestions. To reduce the risk while preserving the delight of binary outcome products, a number of risk mitigation techniques observed in gradual outcomes come in handy.
Think through the product’s confusion matrix
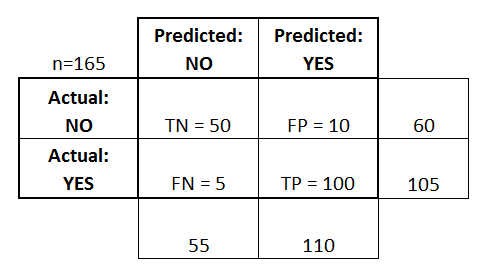
Classification models, which try to predict whether something belongs to a certain group or not are oftentimes used in binary outcomes. (Is this photo of Barack Obama? Is this email spam? Is this blog post wonderful?) In building this type of model, data scientists use a **confusion matrix** to monitor the four quantitative outcomes of the model: **true positives, false positives, true negatives, and false negatives**. Classification models encompass these four outcomes on a regular basis; error is inevitable.
An insightful article from two Google designers, Josh Lovejoy and Jess Holbrook, published last July offers a framework for thinking through ML-driven experiences. A key insight is the use of a confusion matrix for product design: knowing that your users **will ****experience all four outcomes **means you need to design for all four modes.

In the classic “Not Hotdog” use case, the accuracy of the hotdog classifier has no consequence. For Google Photos, seeking to identify pictures of animals, true positives and true negatives that correctly identify animals are table stakes. In this context, incorrectly identifying a gorilla as a human can be thought of as a false negative, with little consequence. Identifying a human as a gorilla, though, as a false positive, is deeply offensive and creates a scandal. By thinking through the confusion matrix during the design phase, you’ll ensure users have a positive experience, no matter the prediction.
Incorporate gradual attributes into binary outcomes
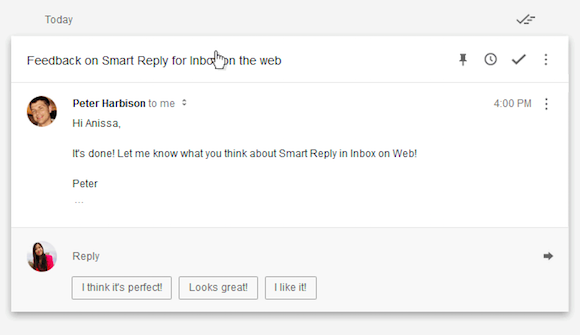
Google Inbox’s automatic responses is a powerful case study, neatly illustrating three UX tactics that lead to success:
Sets of predictions: Inbox provides three suggested replies, greatly lessening the accuracy requirements. If the user selects one of the three, the click can be recorded as positive feedback for the model. If the user ignores the set, all three predictions can be recorded as unhelpful.
Human-in-the-loop: when the user selects an auto-response, it fills the reply window, with the cursor activated for easy customization and sending of the reply.
Escape hatch: if the predicted responses are off the mark, the user ignores them and writes the email as before, with no added annoyance.
This flow scales well beyond email to flows that require even higher accuracy. When radiologists are tasked with identifying malignant cells under a microscope, they start from scratch by scanning the photo with their eyes. Imagine a 70% accurate ML algorithm also scans the image, and draws ten outlines around what it thinks are bad cells. On average, three of the algorithm’s outlines will be wrong and seven will be right. With the right interface, the radiologist is well-positioned to rapidly reject the three bad outlines, approve the seven correct ones, and add new ones, generating a large boost in productivity.
With machine learning, the radiologist speeds through their work. Without the radiologist, 30% of cancer cells would go undetected — a massive failure.
Conclusion
Plenty of newsprint has been used to describe the time and effort that goes into training quality machine learning models. Less has been spent on the equally challenging task of designing applications for those models that delight users.
The incorporation of error not as an after-thought but as the primary consideration is a fundamentally different dynamic for experience design than before. As software designers and architects, we can navigate this complex arena by making informed choices about the role ML should play in solving a task for a user and offering that user complete control around the experience. If ML can help, it should; if it can’t, it needs to get out of the way, quickly. Only your user can tell the difference: don’t forget to help them out.
Like this article? Give it a clap to help others find it.
Comments, corrections? Would love to hear them at gregdale00 at gmail dot com.